Why LLMs might actually lead to AGI
, 8 min read
Search “will llms agi” on Google and you will find completely contradicting opinions.
Sam Altman promises AGI in 2025. Dario Amodei dreams about Machines of Loving Grace. Yann LeCun straightaway declares that scaling LLMs is just complete BS. Ilya Sutskever encourages young researchers to think new ideas, and Francois Chollet struggles to come up with a benchmark that can even define what AGI is.
Still, we’re confidently investing billions of dollars into LLMs. This seems irrational until you understand what problem LLMs actually solve.
The bottleneck of AI progress
AI progress is bounded by research iteration speed and the total amount of energy available for computation.
Research speed means how quickly we can test ideas and make them work in practice. Think of it as the time between researchers conceptualizing “thinking models”, and o1 being live on ChatGPT.
Better algorithms, evals, and model architectures are all research outputs that give us more “intelligence”. New chips, scaling methods, and infrastructure optimizations give us more FLOPs per watt.
Energy for computation means how many watts we have for running AI. Building more datacenters increases our total available wattage.
Since AI is just matrix multiplications at scale, more FLOPs means faster iteration. More FLOPs come from research, and more wattage from datacenter capacity. The combination of the two gives us how many operations we can do, or, how many things we can try.
Everything is reduced to two variables: research speed and energy.
(I won’t talk much about energy in this post.)
What changed within a year
LLMs today can easily make beautiful landing pages and demo apps, contribute to existing codebases, and perform basic tasks in containerized computer environments like ordering pizza or booking tickets. As almost everyone experienced a month ago, AI can now turn any picture into a Ghibli scene and follow visual instructions surprisingly well.
These tasks sound boring, but that’s because the more hype AI gets, the higher our expectations go. A year ago, none of this worked 1. We didn’t even have multimodal or thinking models yet, both of which were instrumental in making agents possible 2.
Within less than a year, we got from AI barely completing toy tasks, to autonomous delivery of economically valuable work.
The image below succinctly summarizes the progress:
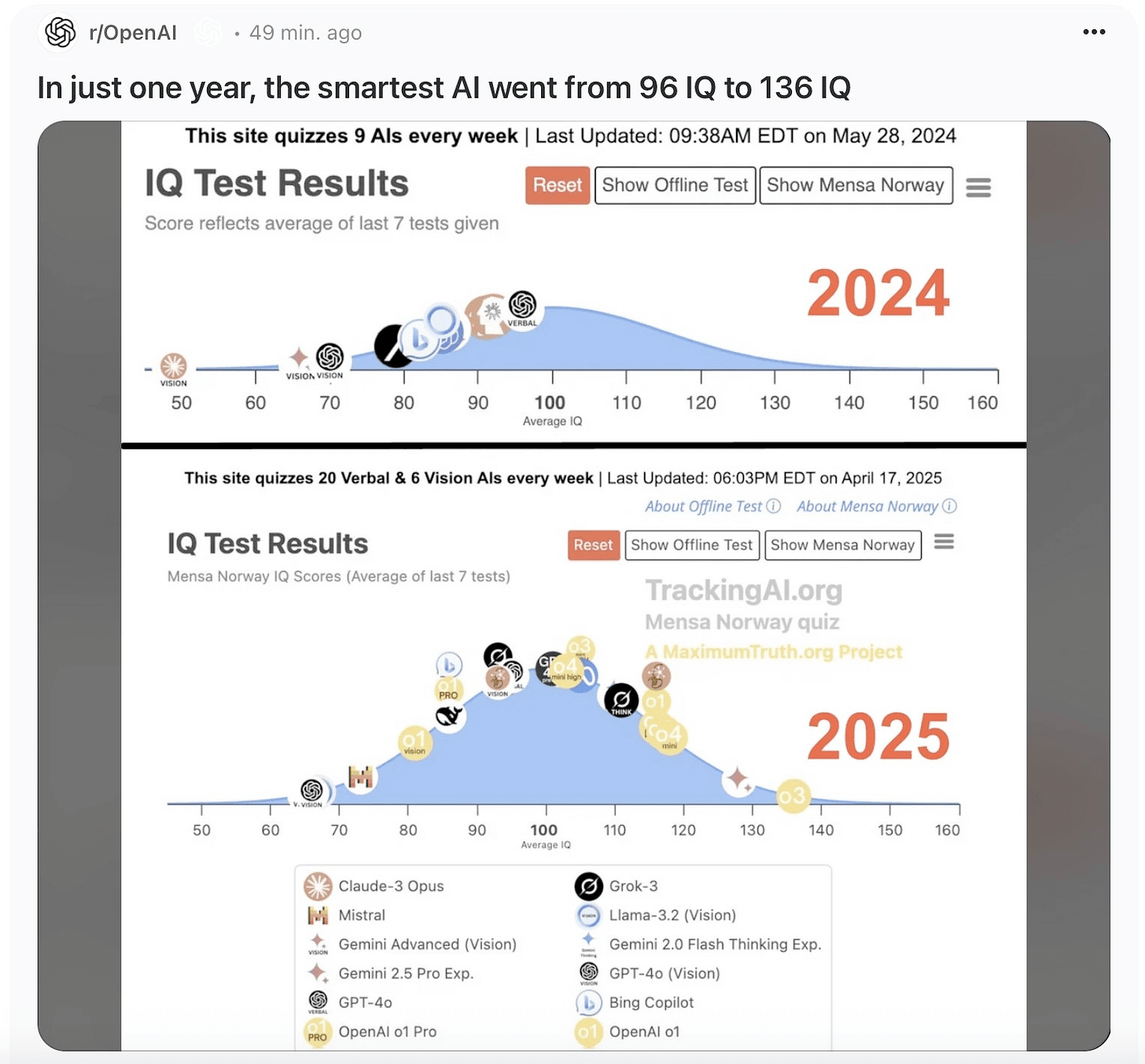
But what does this have to do with AGI? Yes, models are improving fast, but a cat is still, in some ways, more intelligent than an LLM.
I suspect that no person on earth today has any concrete idea how to get to AGI. But we still have a simple path to get there.
AI research is boring work
Walk into any frontier lab and ask a researcher how they spend their week. You will hear about failed training runs that need debugging, broken pipelines that need fixing, hardware issues that they don’t understand.
On a good week, they might get a few hours of actual creative work: designing experiments, formulating hypotheses, interpreting results.
Parsing ten-thousand-line error logs doesn’t require brilliance. Babysitting a job and restarting it when things go wrong isn’t creative. Running multiple experiments with different hyperparameters is tedious. And importantly, humans are remarkably bad at all these tasks.
We are not out of ideas. People have tons of ideas and too little time to try them out. The boring, repetitive work is the bottleneck to AI progress.
LLMs are a research catalyst
We’re left with two statements:
- AI progress is bounded by research speed.
- Much of research is boring work.
If these are true, we should be able to automate research.
Humans are good at having ideas, but exploring multiple similar approaches, parsing lots of information, and debugging are slow and tedious tasks. Machines are excellent at exploring variations, parsing logs, and crunching data, but they don’t know how to interpret the results. The two complement each other.
Which leads us to the main point of this whole thoughtstream:
It doesn’t matter whether LLMs ever lead to AGI. What matters is that they can become research accelerators. LLMs will do the gruntwork that humans are bad and slow at, freeing us to focus on what we’re good at: exploring ideas.
If the secret to AGI is hidden in a combinatorial explosion of experiments and ideas, we now have a few highly trained humans crawling through the possibilities. LLM agents will allow each researcher to supervise a thousand explorations in parallel.
And we are almost there. The only remaining piece is having agents that can handle the boring parts of research.
Early tools like Manus AI and Replit already do useful work. Google is training AI co-scientists and I would be surprised if the others are not exploring similar ideas. My current guess is that the big AI labs will be deploying agents that can do basic research tasks before the end of the year. After that, it will probably take another year for these agents to automate significant parts of the process.
Once LLM agents can run experiments, summarize logs, and debug pipelines, many bottlenecks are gone. We can try more ideas. Good ones get refined faster. That leads to better, more autonomous models, and the whole system accelerates.
Maybe this leads to AGI. Probably it just leads to much better models. Either way, our chances to find the next breakthrough increase.
LLMs are the most straightforward way to meaningfully speed things up.
Notice that there is no magic ingredient here and, importantly, no hand-wavy statements like “AI will recursively improve itself leading to intelligence explosion.” All you need to believe is that LLM agents can automate boring work. This would already be enough for transformative AI improvements and economic growth.
Where this leaves us
Whether or not you believe that LLMs will become AGI, there is no doubt that they will massively accelerate research towards AGI.
Going back to the two constraints for AI progress: research iteration, and energy. LLMs will take care of the speed constraint.
The world’s two superpowers are in a full-throttle arms race to build datacenters and power plants. That’s the energy constraint.
As long as speed and energy are progressing, we are getting closer to AGI. In other words, LLMs might lead to AGI.
Thanks to Masha Stroganova and John Carpenter for reading drafts.
Notes:
- This essay is strictly my personal opinion.
- Essays you should read about AI predictions:
- What 2026 looks like, written in 2021 by Daniel Kokotajlo. It got many things right astonishingly right, but it was thankfully too pessimistic about social predictions.
- The Scaling Hypothesis, written between 2020 and 2022 by Gwern. This was one of the core works that reinforced the idea that scaling results in new capabilities, emergent properties not found in smaller scale.
- Situational Awareness, written mid-2024 by Leopold Aschenbrenner.
- AI 2027, released a few weeks ago by Daniel Kokotajlo, Scott Alexander, and a few others. I read this midway through writing my post. Seeing a similar narrative made me a bit more confident in mine. I think (hope?) that their social predictions are too pessimistic, similar to Daniel’s past essay.
-
You can probably point out toy cases where models could kind of build end-to-end code, or some GitHub repo that attempted “agentic” behavior. In practice, the models needed a lot of handholding, they would fail a lot, and they could only tackle much simpler problems. ↩
-
GPT-4o was released on May 13 2024, and o1 started previewing on September 12 2024. ↩